So, I'm looking for employment in Ohio, or via the internet somewhere else. It seems that everybody is looking for a senior C# programmer. Must have history using Visual Studio/ .NET.
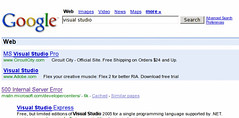
So, I think, time to look into learning C#. And Visual Studio. You see the results at right: Microsoft's top hit is a .NET-powered "internal server error."
Also of note: One of the top ten Google results was "Does Visual Studio Rot The Mind?"
arch detail

Thursday, November 30, 2006
Wednesday, October 18, 2006
Output from IBM's xlc for Cell BE
"flopsie_spu.c", line 56.5: 1506-068 (S) Operation between types "vector float" and
"<><><> Illegal tVectorType!!!" is not allowed.
Oh, IBM xlc, you always make me smile.
Saturday, October 14, 2006
The Cell BE: What works, what doesn't
There's no shortage of talk out there on whether or not the Cell will ever take off. I've been fortunate enough to get some time actually coding it, and I think it's important that I get my personal views out there. The Cell really does present some unique challenges and some unique opportunities for the computing world at large, and its fate will likely decide the future of IBM, and possibly Sony and Toshiba as well.
This is likely to be long, so I'm breaking it down into three areas:
An Introduction briefly defines the Cell architecture and what critics have said about it (i.e., hype and response).
Cell in Practice is the section on the nitty-gritties of how to programming for the Cell within the paradigm provided by IBM. It's intended for programmers and based on my personal experiences, and if you're not a programmer, feel free to skip it.
Conclusions is written for anyone who wants to know what the Cell means to them and the future of the computer industry. Programmers might appreciate it, but you shouldn't need any serious technical knowledge to appreciate it.
An Introduction: What has already been said
The Cell architecture has been hyped and misunderstood on a level few bits of technology ever have. I blame, at least partially, the video game industry and mainstream media for making a lot of noise without much understanding.
But here's the overview of what Cell is:
The Cell architecture is IBM/Sony/Toshiba's new joint investement. It's a radical departure from conventional CPU architectures as we know them today. Rather than one individual CPU on the chip, it actually contains a PPE (Power Processor Element, basically a simplified G5) and eight SPEs (Synergistic Processing Elements, vectorized floating-point optimized processors) which are all connected on a high-bandwidth bus (Element Interface Bus, EIB).
Sony/IBM/Toshiba claim that the Cell will make truly next-gen performance feasible, *and* do it with less power intake than conventional CPUs, which have stagnated in recent years. The low power consumption means that the Cell might be well-suited to making next-generation multimedia and encryption technology possible within handheld devices like cell phones, PDAs and consumer electronics devices like HDTVs. And, of course, the huge perfomance increases for video and multimedia made it a logical choice for the Playstation 3. And eventually, it might even take the desktop computer world.
But this radical departure means that to get better performance out of any application, it has to be hand-recoded, paralellized and retuned for the Cell architecture. You can recompile your app for the new architecture, but it will only use the PPE, but it'll actually run slower than on an older G5.
And naturally, this is the main argument made against any hope of the Cell taking off: every architecture in history has taken off because of the amount of legacy software it can run; how else can you explain the way the monstrous Intel x86/Windows paradigm has conquered the world? Any processor that actually lowers performance for most applications - and won't run, say, Windows or MS Office, erm, anytime soon - doesn't seem to be a likely candidate for the future of computing.
Cell in Practice: A practical example of programming the Cell BE
I've had the good fortune of exploring the performance of the Cell for a week now, and it's been a sometimes-frustrating but ultimately rewarding experience. In fact, I used IBMs vectorized 1D FFT to create my own 2D FFT library (not quite finished, hopefully soon to be on SourceForge.) Here's how the real programming paradigm works out, at least for me, and the associated pitfalls:
IBM has released a SDK and system simulator under the Common Public License. The SDK contains a few helpful examples, though the code can be a little perplexing at times. They also will provide you with modified versions of GCC and associated GNU tools, as well as the IBM XLC compilers for Cell, free of charge.
Perhaps most importantly, there are example Makefiles in the SDK. You'll want to look long and hard at those. Since the PPE and SPEs are effectively different architectures, you'll need to write and compile separate code for both of them, then *link* the SPE program into the PPE program so that the PPE can spawn SPE threads on the 8 SPEs.
This is where we start to run into some of the hassles of coding for the SPEs. The SPEs keep everything in "Local Store", which is basically an L2 Cache. The size of the LS on the Cell BE is 256KB/SPE, but that can change on future Cell models. Furthermore, you'll have to explicitly manage movement between main memory and Local Stores - and you'll have to factor in the size of your running code when you calculate your memory requirements. There is nothing like virtual memory to help you. I understand that if you've done programming for a GPU, this isn't anything new, but it was very new to me.
You'll have to figure out what you want those SPEs doing, of course, and you need to put them to good use if you want to get any speedup out of this architecture. Fortunately for me, a 2D FFT is well-suited; just break up the image into 8 column-wise segements, then distribute them from main memory to SPE Local Stores with IBM's Direct Memory Access (DMA) library and process them one column at a time on the SPEs, then move them back to the main store using DMA.
A quick pitfall of using IBM's DMA: SPEs cannot access any data that is not allocated in a global scope in C. This took quite a while for me to figure out, and it means that you'll have to get past the "good programming practices" verboten on global allocation and statically allocate a huge buffer for communicating with the SPUs.
To get peak performance for DMA transfers, IBM claims that carefully using their other C extensions like __attribute__ ((alignment (128))) will speed up DMAs and vector ops, but I didn't personally find this to be the case - the compilers seemingly took care of this for me, as my benchmarking experiments didn't seem to show any difference when I attempted this level of optimization.
The next step to optimizing this one was to use a vectorized 1D FFT. IBM provides you with C/C++ extensions for declaring vector data types and a bunch of vector math functions that do a straight 1-to-1 mapping from C functions like vec_add or spu_add straight to the corresponding assembly functions. Getting them set up is definitely a tad confusing, though; you'll need to include header files and make sure to use the IBM-distributed compilers with the correct option flags, and any erroneous usage of vector calls will result in completely perplexing compiler messages.
Fortunately for me, IBM provide a vectorized 1D FFT, unhelpfully provided under the misnomer fft_2d, and they give an example in the documentation.
Shockingly, their example of fft_2d usage in the users guide would actually cause an "unexpected internal compiler error" in spuxlc, the XLC compiler. Fortunately, when I informed IBM on the developer's forums, they were quick to respond that the example was bad (it required more memory than one could possibly allocate on an SPE) and promise that the compiler would be fixed by the next drop, but I never got any word on an improved example for the users guide. It was the first hint I've seen that IBM must be getting desperate - the Cell Blade server is on the market, and it's a little late to play the "it's just pre-release!" game with users now.
After some initial testing, it became obvious that DMA was a huge portion of my execution time, because of the fact that I was waiting on data every time I requested it, my DMA transfers were becoming a huge burden. Requesting 4-6 accessed at a time and then waiting on the data only when I absolutely needed it ended up giving me something along the lines of a 6x speedup.
Now comes the next phase of development: Starting over. Why? Well, in my case, it turns out that the vectorized FFT approach means I don't have memory for double-buffering, and it sure looks like vectorization in this case is a lot less helpful than lowering my DMA wait times. So call my library incomplete for now.
For all this work, was it worth the effort?
Well, consider my surprise when I compared my dinky, incomplete FFT lib's performance to the performance of FFTW (the Fastest Fourier Transform in the West) running on Itanium (at NCSA's TeraGrid site) and on my local 2.8 GHz Pentium 4.
The results?
I beat them both. Yep. My first attempt at any kind of FFT library, and also my first attempt at programming the Cell (and this from a guy who's never done graphics *or* embedded systems, the two things that would make you well-qualified for Cell programming) was enough to beat out the highest stage of FFT evolution on Intel architectures. And my library only stands to get better.
Bearing in mind that FFTs are one of the most heavily-used tools in science and multimedia (both sound and video), this is no small news. Not everyone gets to knock out the champ on their first shot.
On the other hand, this is purely an in-core FFT - FFTW will scale to huge resolutions independent of L2 cache size. My version will have to discard vectorization for anything above 2048 x 2048 (which I might do anyway) and then will need to completely rewritten for anything that exceeds 16K x 16K. This is entirely because of the fact that the SPEs are completely restricted to local store, and dealing with memory usage beyond those bounds is completely the responsibility of the programmer.
So if you want to use this library for larger-sized 2D FFTs, you'll need to either wait for IBM to release a Cell with a larger Local Store - size is not specified in the design specs; so Local Store size could increase or decrease at any time - or use another library.
There are some other funny caveats for programmers, and with some funny implications for the consumer world.
First: Statically compiled libraries are the only ones you can use in the SPEs. This is because the libraries *and* your code *and* your data all have to live on the Local Store. The biggest restriction on performance in the SPEs, at least in my experience, is the size of the Local Store. Thus, choice of libraries and choice of compiler are both going to have significant effects on how much space you have left to allocate for actually doing work. This is certainly going to require some interesting programming approaches, and I highly doubt it will make for more readable code!
Further, it also means that if all your library, bar, contains a statically compiled library foo, you'll have to recompile bar every time foo is upgraded. And you can imagine that this will quickly get out of control.
Second: Be careful about your assumptions regarding how much data space you can use in the SPEs. The size of the Local Store could change at any time with new models of Cells. This might make your life easier if Local Stores get bigger. It might also mean that you run into a lot of trouble if your library needs to run on a scaled-down Cell for portable devices.
Third: Don't kid yourself about using a high-level language for optimized coding on the Cell. It just won't ever happen. However, *do* seriously consider using a high-level language like Python that is highly flexible and can use C libraries. Someone will soon write extensions to Python that can take care of things like heavy-duty floating point math on the Cell, and Python should be able to use them quite nicely. Though admittedly, I'm not positive what this means for all those globally-declared buffers you'll need for communication between PPE and SPEs, but realistically, someone smarter than me *has* to find a fix.
This means that while programming for the Cell is a trip into the world of assembly, and many complain about it being a big step backwards, it actually enforces the separation between low-level functionality and high-level functionality. Expect to see existing Python applications be the first ones ported to Cell and utilizing its real horsepower - not long after C programmers bring heavy-hitting, SPE-aware libraries to the Cell.
Conclusions: What you need to know if you're contemplating a purchase
Sony, IBM and Toshiba are certainly hoping the Cell will become the dominant architecture of the coming decades. I don't see this happening. I'm not sure we'll be seeing Cell processors in PDAs and Cell phones and HDTVs like they predict. I don't think the Cell will ever reach the critical mass of popularity where market forces make it dramatically cheaper, as we saw with Intel processors.
However, for serious scientific programming, expect this thing to take some serious market share, and for good reason. Critics point out that there is a major barrier for adoption - much of the code needed to harness the power of Cell needs to be rewritten, so if you're buying a Cell, factor in the hidden cost of hiring one or more programmers to make use of it.
Make sure to consult with programmers first. Knowing your application and knowing what existing Cell-optimized libraries it might use could mean the difference between weeks or months of development time and a few hours. And programming for the Cell is easy and rewarding enough that you can realistically expect some Cell-optimized libraries within the next year or so.
Since IBM released their SDK under the Common Public License, any code that uses their SDK can be made public under the same license, but can also be compiled into proprietary applications. Hopefully we'll soon see a GPL alternative for the Free-as-in-speech world, but for now, if you need to get a job done (for cash or for academia) you have the freedom to do either with the tools IBM has given you.
The Cell for home use is on the horizon, but if you're an overclocking geek looking to get Playstation 3 graphics out of your home desktop: well, don't hold your breath.
This is likely to be long, so I'm breaking it down into three areas:
An Introduction briefly defines the Cell architecture and what critics have said about it (i.e., hype and response).
Cell in Practice is the section on the nitty-gritties of how to programming for the Cell within the paradigm provided by IBM. It's intended for programmers and based on my personal experiences, and if you're not a programmer, feel free to skip it.
Conclusions is written for anyone who wants to know what the Cell means to them and the future of the computer industry. Programmers might appreciate it, but you shouldn't need any serious technical knowledge to appreciate it.
An Introduction: What has already been said
The Cell architecture has been hyped and misunderstood on a level few bits of technology ever have. I blame, at least partially, the video game industry and mainstream media for making a lot of noise without much understanding.
But here's the overview of what Cell is:
The Cell architecture is IBM/Sony/Toshiba's new joint investement. It's a radical departure from conventional CPU architectures as we know them today. Rather than one individual CPU on the chip, it actually contains a PPE (Power Processor Element, basically a simplified G5) and eight SPEs (Synergistic Processing Elements, vectorized floating-point optimized processors) which are all connected on a high-bandwidth bus (Element Interface Bus, EIB).
Sony/IBM/Toshiba claim that the Cell will make truly next-gen performance feasible, *and* do it with less power intake than conventional CPUs, which have stagnated in recent years. The low power consumption means that the Cell might be well-suited to making next-generation multimedia and encryption technology possible within handheld devices like cell phones, PDAs and consumer electronics devices like HDTVs. And, of course, the huge perfomance increases for video and multimedia made it a logical choice for the Playstation 3. And eventually, it might even take the desktop computer world.
But this radical departure means that to get better performance out of any application, it has to be hand-recoded, paralellized and retuned for the Cell architecture. You can recompile your app for the new architecture, but it will only use the PPE, but it'll actually run slower than on an older G5.
And naturally, this is the main argument made against any hope of the Cell taking off: every architecture in history has taken off because of the amount of legacy software it can run; how else can you explain the way the monstrous Intel x86/Windows paradigm has conquered the world? Any processor that actually lowers performance for most applications - and won't run, say, Windows or MS Office, erm, anytime soon - doesn't seem to be a likely candidate for the future of computing.
Cell in Practice: A practical example of programming the Cell BE
I've had the good fortune of exploring the performance of the Cell for a week now, and it's been a sometimes-frustrating but ultimately rewarding experience. In fact, I used IBMs vectorized 1D FFT to create my own 2D FFT library (not quite finished, hopefully soon to be on SourceForge.) Here's how the real programming paradigm works out, at least for me, and the associated pitfalls:
IBM has released a SDK and system simulator under the Common Public License. The SDK contains a few helpful examples, though the code can be a little perplexing at times. They also will provide you with modified versions of GCC and associated GNU tools, as well as the IBM XLC compilers for Cell, free of charge.
Perhaps most importantly, there are example Makefiles in the SDK. You'll want to look long and hard at those. Since the PPE and SPEs are effectively different architectures, you'll need to write and compile separate code for both of them, then *link* the SPE program into the PPE program so that the PPE can spawn SPE threads on the 8 SPEs.
This is where we start to run into some of the hassles of coding for the SPEs. The SPEs keep everything in "Local Store", which is basically an L2 Cache. The size of the LS on the Cell BE is 256KB/SPE, but that can change on future Cell models. Furthermore, you'll have to explicitly manage movement between main memory and Local Stores - and you'll have to factor in the size of your running code when you calculate your memory requirements. There is nothing like virtual memory to help you. I understand that if you've done programming for a GPU, this isn't anything new, but it was very new to me.
You'll have to figure out what you want those SPEs doing, of course, and you need to put them to good use if you want to get any speedup out of this architecture. Fortunately for me, a 2D FFT is well-suited; just break up the image into 8 column-wise segements, then distribute them from main memory to SPE Local Stores with IBM's Direct Memory Access (DMA) library and process them one column at a time on the SPEs, then move them back to the main store using DMA.
A quick pitfall of using IBM's DMA: SPEs cannot access any data that is not allocated in a global scope in C. This took quite a while for me to figure out, and it means that you'll have to get past the "good programming practices" verboten on global allocation and statically allocate a huge buffer for communicating with the SPUs.
To get peak performance for DMA transfers, IBM claims that carefully using their other C extensions like __attribute__ ((alignment (128))) will speed up DMAs and vector ops, but I didn't personally find this to be the case - the compilers seemingly took care of this for me, as my benchmarking experiments didn't seem to show any difference when I attempted this level of optimization.
The next step to optimizing this one was to use a vectorized 1D FFT. IBM provides you with C/C++ extensions for declaring vector data types and a bunch of vector math functions that do a straight 1-to-1 mapping from C functions like vec_add or spu_add straight to the corresponding assembly functions. Getting them set up is definitely a tad confusing, though; you'll need to include header files and make sure to use the IBM-distributed compilers with the correct option flags, and any erroneous usage of vector calls will result in completely perplexing compiler messages.
Fortunately for me, IBM provide a vectorized 1D FFT, unhelpfully provided under the misnomer fft_2d, and they give an example in the documentation.
Shockingly, their example of fft_2d usage in the users guide would actually cause an "unexpected internal compiler error" in spuxlc, the XLC compiler. Fortunately, when I informed IBM on the developer's forums, they were quick to respond that the example was bad (it required more memory than one could possibly allocate on an SPE) and promise that the compiler would be fixed by the next drop, but I never got any word on an improved example for the users guide. It was the first hint I've seen that IBM must be getting desperate - the Cell Blade server is on the market, and it's a little late to play the "it's just pre-release!" game with users now.
After some initial testing, it became obvious that DMA was a huge portion of my execution time, because of the fact that I was waiting on data every time I requested it, my DMA transfers were becoming a huge burden. Requesting 4-6 accessed at a time and then waiting on the data only when I absolutely needed it ended up giving me something along the lines of a 6x speedup.
Now comes the next phase of development: Starting over. Why? Well, in my case, it turns out that the vectorized FFT approach means I don't have memory for double-buffering, and it sure looks like vectorization in this case is a lot less helpful than lowering my DMA wait times. So call my library incomplete for now.
For all this work, was it worth the effort?
Well, consider my surprise when I compared my dinky, incomplete FFT lib's performance to the performance of FFTW (the Fastest Fourier Transform in the West) running on Itanium (at NCSA's TeraGrid site) and on my local 2.8 GHz Pentium 4.
The results?
I beat them both. Yep. My first attempt at any kind of FFT library, and also my first attempt at programming the Cell (and this from a guy who's never done graphics *or* embedded systems, the two things that would make you well-qualified for Cell programming) was enough to beat out the highest stage of FFT evolution on Intel architectures. And my library only stands to get better.
Bearing in mind that FFTs are one of the most heavily-used tools in science and multimedia (both sound and video), this is no small news. Not everyone gets to knock out the champ on their first shot.
On the other hand, this is purely an in-core FFT - FFTW will scale to huge resolutions independent of L2 cache size. My version will have to discard vectorization for anything above 2048 x 2048 (which I might do anyway) and then will need to completely rewritten for anything that exceeds 16K x 16K. This is entirely because of the fact that the SPEs are completely restricted to local store, and dealing with memory usage beyond those bounds is completely the responsibility of the programmer.
So if you want to use this library for larger-sized 2D FFTs, you'll need to either wait for IBM to release a Cell with a larger Local Store - size is not specified in the design specs; so Local Store size could increase or decrease at any time - or use another library.
There are some other funny caveats for programmers, and with some funny implications for the consumer world.
First: Statically compiled libraries are the only ones you can use in the SPEs. This is because the libraries *and* your code *and* your data all have to live on the Local Store. The biggest restriction on performance in the SPEs, at least in my experience, is the size of the Local Store. Thus, choice of libraries and choice of compiler are both going to have significant effects on how much space you have left to allocate for actually doing work. This is certainly going to require some interesting programming approaches, and I highly doubt it will make for more readable code!
Further, it also means that if all your library, bar, contains a statically compiled library foo, you'll have to recompile bar every time foo is upgraded. And you can imagine that this will quickly get out of control.
Second: Be careful about your assumptions regarding how much data space you can use in the SPEs. The size of the Local Store could change at any time with new models of Cells. This might make your life easier if Local Stores get bigger. It might also mean that you run into a lot of trouble if your library needs to run on a scaled-down Cell for portable devices.
Third: Don't kid yourself about using a high-level language for optimized coding on the Cell. It just won't ever happen. However, *do* seriously consider using a high-level language like Python that is highly flexible and can use C libraries. Someone will soon write extensions to Python that can take care of things like heavy-duty floating point math on the Cell, and Python should be able to use them quite nicely. Though admittedly, I'm not positive what this means for all those globally-declared buffers you'll need for communication between PPE and SPEs, but realistically, someone smarter than me *has* to find a fix.
This means that while programming for the Cell is a trip into the world of assembly, and many complain about it being a big step backwards, it actually enforces the separation between low-level functionality and high-level functionality. Expect to see existing Python applications be the first ones ported to Cell and utilizing its real horsepower - not long after C programmers bring heavy-hitting, SPE-aware libraries to the Cell.
Conclusions: What you need to know if you're contemplating a purchase
Sony, IBM and Toshiba are certainly hoping the Cell will become the dominant architecture of the coming decades. I don't see this happening. I'm not sure we'll be seeing Cell processors in PDAs and Cell phones and HDTVs like they predict. I don't think the Cell will ever reach the critical mass of popularity where market forces make it dramatically cheaper, as we saw with Intel processors.
However, for serious scientific programming, expect this thing to take some serious market share, and for good reason. Critics point out that there is a major barrier for adoption - much of the code needed to harness the power of Cell needs to be rewritten, so if you're buying a Cell, factor in the hidden cost of hiring one or more programmers to make use of it.
Make sure to consult with programmers first. Knowing your application and knowing what existing Cell-optimized libraries it might use could mean the difference between weeks or months of development time and a few hours. And programming for the Cell is easy and rewarding enough that you can realistically expect some Cell-optimized libraries within the next year or so.
Since IBM released their SDK under the Common Public License, any code that uses their SDK can be made public under the same license, but can also be compiled into proprietary applications. Hopefully we'll soon see a GPL alternative for the Free-as-in-speech world, but for now, if you need to get a job done (for cash or for academia) you have the freedom to do either with the tools IBM has given you.
The Cell for home use is on the horizon, but if you're an overclocking geek looking to get Playstation 3 graphics out of your home desktop: well, don't hold your breath.
Friday, October 06, 2006
Cell simulator screenshot
Not-high-enough-res screenshot of a running Cell BE virtual machine. A bit of a drudge to use, but damned if I'm not giddy. It's basically like being ssh-ed in and X-forwarding from a very slow machine - pictured here actually *booting* Fedora Core 5.
Very neat, though it doesn't model penalties for memory access (which is, as far as I can tell, the biggest threat to Cell performance) and/or the actual PPU (Power-PC unit, the core of the machine), just the behavior of the SPUs (the eight floating-point, graphics-card-esque units attached to the PPU).
Very neat, though it doesn't model penalties for memory access (which is, as far as I can tell, the biggest threat to Cell performance) and/or the actual PPU (Power-PC unit, the core of the machine), just the behavior of the SPUs (the eight floating-point, graphics-card-esque units attached to the PPU).
The Five Stages of Beginning Cell BE Programming
I'm only at the LSST for another month, and Tim, my boss, has suggested that I use the remainder of my time not on our prototype code but on playing with the Cell architecture.
My response to this has been broken into several stages:
1) Joyful excitement. Goodbye, UML! Goodbye, boring software engineering assignments! Hello to the exploring the hot-topic design of the new millenium!
2) Confusion! The media was not meant for computer science. Google "Cell architecture" and you'll hear nonsense that will blow your mind - "its the desktop on a chip!" "It's a global grid infrastructure!" "It's SkyNet!" and of course, the obvious backlash - "It's just a G4!" "It's a bunch of hype!" "It's Sony's downfall and IBM's Itanic!" Suddenly, finding realistic information not provided by IBM is impossible, and it's nearly as hard not to love or hate this thing before even understanding it.
3) Puzzled looks at the IBM website. Corporate websites are bad enough, but you'd think IBM would get the picture. There's a simulator, once you create an IBM ID; and, oh, wait, the simulator is part of the SDK? And half the necessary files are on the Barcelona Supercomputing Center website? And installing Fedora (Core 5 only!) is *required* to get it to run?
4) Frustration. The install script never works correctly. The Barcelona page is completely spazzy. Leave the download script running overnight and hope that it will finish before coming back to work. Arrrrghhhh.
5) Renewed excitement. You have to write separate programs for the separate components of the CPU? You have to be running the *simulated* version just to get any kind of terminal I/O (i.e. printf) from the 8 SPUs on the chip that do most of the computation? Is this a trip to the future or into the assembly programming days? Can this really ever fly? Will the install script ever work?
My response to this has been broken into several stages:
1) Joyful excitement. Goodbye, UML! Goodbye, boring software engineering assignments! Hello to the exploring the hot-topic design of the new millenium!
2) Confusion! The media was not meant for computer science. Google "Cell architecture" and you'll hear nonsense that will blow your mind - "its the desktop on a chip!" "It's a global grid infrastructure!" "It's SkyNet!" and of course, the obvious backlash - "It's just a G4!" "It's a bunch of hype!" "It's Sony's downfall and IBM's Itanic!" Suddenly, finding realistic information not provided by IBM is impossible, and it's nearly as hard not to love or hate this thing before even understanding it.
3) Puzzled looks at the IBM website. Corporate websites are bad enough, but you'd think IBM would get the picture. There's a simulator, once you create an IBM ID; and, oh, wait, the simulator is part of the SDK? And half the necessary files are on the Barcelona Supercomputing Center website? And installing Fedora (Core 5 only!) is *required* to get it to run?
4) Frustration. The install script never works correctly. The Barcelona page is completely spazzy. Leave the download script running overnight and hope that it will finish before coming back to work. Arrrrghhhh.
5) Renewed excitement. You have to write separate programs for the separate components of the CPU? You have to be running the *simulated* version just to get any kind of terminal I/O (i.e. printf) from the 8 SPUs on the chip that do most of the computation? Is this a trip to the future or into the assembly programming days? Can this really ever fly? Will the install script ever work?
Friday, September 29, 2006
Musings on the Flaws of *NIX Shells
I spend most of my time during the day running shell commands. They're the fastest way to get complex (and even very simple) tasks done. I do plenty of writing code in other, more serious languages, but I'm somewhat hesitant to admit that I've never been good with any shell. I'm getting there, but boy, is it frustrating. And it's taken me years to deal with that frustration instead of running off to stronger tools like, say, C.
But you know what? That shouldn't have to be the case.
Let me start by bringing up an issue that's always irked me. Say you're using BASH (though tcsh, csh, zsh are all going to do pretty much the same thing here). You want to, say, cat a file with spaces in its name. (For the uninitiated, 'cat' takes a variable number of arguments, which are names of files, and then prints their contents.) So call our file
Fortunately, the original UNIX shell designers realized that you might want to use spaces in filenames. Good call. After all, we're not DOS users, here.
So how about we do this?
Okay, so that makes sense. Because those quotes escaped the spaces for the MYVAR= command, and then were discarded, setting the value of MYVAR to
So let's fix that code! We'll put quotes inside the quotes and get a quoted string for MYVAR! Now the shell will extract those quotes and send cat the parameter (singular) that we wanted.
Now, say that we're shell designers and we're thinking this stuff up. The above is a pretty good decision. After all, if it weren't the case, how would you set MYVAR to the values
However, we've created a syntactic hole for ourselves now. How can we have our shell be smart enough to understand when the quotes in a variable are supposed to be interpreted by the shell? Tough question.
So there's another route - manually escape the spaces using the escape character \ (backslash). So we do this:
But now say that the program foobar gives us the output
Okay, so you say, there must be a way around this. And there is. You just have to learn the wonder of sed!
The problem I'm beating over everyone's head here is this: To really accomplish everything you need in a shell, you need to learn more than a shell, you need to learn UNIX tradition. That's great and all, I guess, but wouldn't it be better if the shell could really do everything you need? Like maybe process all those strings in a more intelligent way without external tools like perl, or sed, or Python?
In short, this is how I think things were (ideally) meant to work:
The above leads me to conclude that what we really need is a new way of thinking about shells, and a new way to make shells fulfill the above criteria. Right now they don't, and please, don't tell me that making sed into a BASH-builtin will change this issue.
And as you might have figured out from the above distinction between side effects and expression/computation, my mind is looking in the direction of functional programming - and its ill-loved, underappreciated bastard-child, LISP.
But you know what? That shouldn't have to be the case.
Let me start by bringing up an issue that's always irked me. Say you're using BASH (though tcsh, csh, zsh are all going to do pretty much the same thing here). You want to, say, cat a file with spaces in its name. (For the uninitiated, 'cat' takes a variable number of arguments, which are names of files, and then prints their contents.) So call our file
a b c.txtAs you probably know, shells differentiate (tokenize) arguments based on spaces (using spaces as delimiters). So
cat a b c.txtwill give errors - it tries to print the file a, then the file b, then the file c.txt. Whoops.
Fortunately, the original UNIX shell designers realized that you might want to use spaces in filenames. Good call. After all, we're not DOS users, here.
cat "a b c.txt"does what we wanted. Great, you say. Problem solved.
So how about we do this?
MYVAR="a b c.txt"We again get contents of a, b, and c.txt, not of our target file. Whoops again!
cat $MYVAR
Okay, so that makes sense. Because those quotes escaped the spaces for the MYVAR= command, and then were discarded, setting the value of MYVAR to
a b c.txt. Makes sense.
So let's fix that code! We'll put quotes inside the quotes and get a quoted string for MYVAR! Now the shell will extract those quotes and send cat the parameter (singular) that we wanted.
MYVAR="\"a b c.txt\""Uh-oh! Instead, cat got three parameters again - this time they were
cat $MYVAR
"aNow, this makes sense, frustrating though it is (at first). Because after all, the real meaning of double-quotes is "spaces inside of here (and several other special characters we won't mention) are to be taken literally, not interpreted by the shell."
b
c.txt"
Now, say that we're shell designers and we're thinking this stuff up. The above is a pretty good decision. After all, if it weren't the case, how would you set MYVAR to the values
"aanyway? It might be important to do so.
b
c.txt"
However, we've created a syntactic hole for ourselves now. How can we have our shell be smart enough to understand when the quotes in a variable are supposed to be interpreted by the shell? Tough question.
So there's another route - manually escape the spaces using the escape character \ (backslash). So we do this:
MYVAR=a\ b\ c.txtWhoohoo! We did it! Go, you mighty gods of UNIX, you Stephen Bournes out there, you really did use good sense.
cat $MYVAR
But now say that the program foobar gives us the output
and we need, say, cat both those files. Okay. That's fine. We could try
"a b c.txt"
"h i j.txt"
cat `foobar`but no! Unwise, you say. It's the same problem we had before. The shell doesn't interpret the output of foobar, silly, it just passes each space-delimited token on to cat, so we try to cat the following files:
and at best get complaints about those files not existing, at worst (and this is a serious problem) get the wrong files cat-ed. Yike!
"a
b
c.txt"
"h
i
j.txt"
Okay, so you say, there must be a way around this. And there is. You just have to learn the wonder of sed!
cat `foobar | sed -e s/ /\\\\\ /g -e s/\"//g`(at least, I think that's it.) Right? What could be easier and more logical? And of course, sed isn't part of the shell, so boy, you're in a lot of trouble right now if you want this to work in a more limited environment. And make sure it's GNU sed; otherwise it might not work quite as expected. Oh, and make sure it's in your path.
The problem I'm beating over everyone's head here is this: To really accomplish everything you need in a shell, you need to learn more than a shell, you need to learn UNIX tradition. That's great and all, I guess, but wouldn't it be better if the shell could really do everything you need? Like maybe process all those strings in a more intelligent way without external tools like perl, or sed, or Python?
In short, this is how I think things were (ideally) meant to work:
- The shell is your operating environment. It should be relatively self-contained.
- (Non-shell) programs are things that we should run because they do something to files, or to the system, or to each other. In this sense, we can think of them as state-changers; and as such, we can think of their jobs as side effects, as computer science folk say. (They might also do calculation; they're better than the shell for this because they're generally faster, but we'll deal with that later.)
- Conversely, the shell should take care of expressive issues - the issues of how to direct programs to do what we want, and to coordinate them to do our bidding. (Computation, the lambda calculus teaches us, is an expressive issue, but as noted before, programs might want to do that, too).
The above leads me to conclude that what we really need is a new way of thinking about shells, and a new way to make shells fulfill the above criteria. Right now they don't, and please, don't tell me that making sed into a BASH-builtin will change this issue.
And as you might have figured out from the above distinction between side effects and expression/computation, my mind is looking in the direction of functional programming - and its ill-loved, underappreciated bastard-child, LISP.
Tuesday, September 12, 2006
strace: A Great Tool I Never Noticed
I ran across this article completely accidentally, and now I'm gawking at myself and wondering why I didn't really know about this stuff. Make your life easier, Linux folksen:
All about Linux: strace - A very powerful troubleshooting tool for all Linux users
All about Linux: strace - A very powerful troubleshooting tool for all Linux users
Wednesday, September 06, 2006
iSight Experiences
I recently picked up an iSight for my girlfriend and nabbed a spare one from work (which, of course, will be returned... eventually) and started exploring the wonderful world of iChat A/V.
All in all, I'm quite impressed - it's one of the few handy-dandy out-of-the-box Mac OS X things that makes me really very glad I have a G4 laying around. It's easy enough for everybody, and it actually makes this temporary long-distance situation between C. Rose and I quite a bit easier. I enjoy it for audio over a cell phone, and the video quality is shockingly good.
I have heard that it works much better between to OS X boxes than between OS X and Windows (or as the guy at the store said, "Mac to PC" - seriously, people, PC is not the inverse of Mac - but that's a rant for another time), so I assume that there must be some major scheduling hacks going on in the kernel to make it so silky-smooth.
The one significant problem, though - and it's a doozy - is that iChat now sporadically causes my Linksys Wireless-G router to take a hard dive. The lights on the front panel keep blinking, but connection between LAN and internet goes away. At first I blamed Cox, the famously questionable service provider, but I found that power cycling my router results in the problems going away.
This is a pretty perplexing situation, and thus far I haven't Googled up any explanation. Will post on further information.
All in all, I'm quite impressed - it's one of the few handy-dandy out-of-the-box Mac OS X things that makes me really very glad I have a G4 laying around. It's easy enough for everybody, and it actually makes this temporary long-distance situation between C. Rose and I quite a bit easier. I enjoy it for audio over a cell phone, and the video quality is shockingly good.
I have heard that it works much better between to OS X boxes than between OS X and Windows (or as the guy at the store said, "Mac to PC" - seriously, people, PC is not the inverse of Mac - but that's a rant for another time), so I assume that there must be some major scheduling hacks going on in the kernel to make it so silky-smooth.
The one significant problem, though - and it's a doozy - is that iChat now sporadically causes my Linksys Wireless-G router to take a hard dive. The lights on the front panel keep blinking, but connection between LAN and internet goes away. At first I blamed Cox, the famously questionable service provider, but I found that power cycling my router results in the problems going away.
This is a pretty perplexing situation, and thus far I haven't Googled up any explanation. Will post on further information.
Monday, August 28, 2006
HOWTO: Subversion over SSH with different usernames
I was recently faced with the problem of needing to check out a Subversion repository on a machine where I had one username onto a machine where I had another.
This was deceptively difficult.
The problem is, svn checkout has a --username ARG option, but that only applies to Subversion. We use svn+ssh:// for security.
I tried the obvious things - svn+ssh://[user]@[host], etc - but nothing worked. After butting my head for a while, I decided to actually read up on how to do this.
Well, Subversion will let you define your own tunnelling protocol if you define the programs which they use. The trick is this: In your ~/.subversion/config, create an entry along these lines:
Then create a BASH script somewhere in your path called dummyssh and make it executable. The script should basically be this:
Now you just do
And you can pull it off.
I have to admit, I wish the Subversion manual included this information. Hope somebody finds it useful.
This was deceptively difficult.
The problem is, svn checkout has a --username ARG option, but that only applies to Subversion. We use svn+ssh:// for security.
I tried the obvious things - svn+ssh://
Well, Subversion will let you define your own tunnelling protocol if you define the programs which they use. The trick is this: In your ~/.subversion/config, create an entry along these lines:
dummyssh = dummyssh
Then create a BASH script somewhere in your path called dummyssh and make it executable. The script should basically be this:
#!/bin/bash
ssh -l[your username] $*
Now you just do
svn checkout --usernamesvn+dummyssh://[host]
And you can pull it off.
I have to admit, I wish the Subversion manual included this information. Hope somebody finds it useful.
LISP as an XML Replacement
This discussion deserves much more attention. Particularly on my part.
The abstract version: you think LISP is a pain? Actually, XML is a lot *more* painful, and we use it when we *should* use LISP, because people are terrified of LISP.
Prof. Salter at my alma mater, Oberlin College, made a big deal about Scheme. Nobody much appreciated it at the time, but I took his pet class, Programming Languages, my senior year, and when it came time to write some compilers in a hurry, it was amazing how after staring at the screen long enough, enlightenment came and the code would just write itself. It was enough to make me a believer.
Tragically, LISP is not Scheme, but if I can get that experience when trying to deal with actual real-life problems (like the ones XML seeks to solve) I'd be willing to learn.
The abstract version: you think LISP is a pain? Actually, XML is a lot *more* painful, and we use it when we *should* use LISP, because people are terrified of LISP.
Prof. Salter at my alma mater, Oberlin College, made a big deal about Scheme. Nobody much appreciated it at the time, but I took his pet class, Programming Languages, my senior year, and when it came time to write some compilers in a hurry, it was amazing how after staring at the screen long enough, enlightenment came and the code would just write itself. It was enough to make me a believer.
Tragically, LISP is not Scheme, but if I can get that experience when trying to deal with actual real-life problems (like the ones XML seeks to solve) I'd be willing to learn.
The Joy of Eshell
Fellow emacsers:
Today I got embarassed because Friday at work I'd used M-x shell in front of a coworker to commit a source change to Subversion. Emacs' shell doesn't hide passwords, so I unintentionally typed mine in plain-text... in front of someone I would like to actually impress.
Whoops.
Naturally, this morning, I decided to see if anyone had though to deal with this problem, and I discovered eshell which has actually been part of emacs since v. 21. Just run M-x eshell.
eshell which has actually been part of emacs since v. 21. Just run M-x eshell.
There are quite a few things that make eshell different than having emacs open a shell inside of its goofy psuedo-terminal buffer. First of all, it's actually a shell. Just for emacs. Written in elisp. Here are some highlights:
There are some problems - see the wishlist on the wiki. Doing a for loop into a pipe doesn't really work correctly. But that's what BASH one-liners are for.
Today I got embarassed because Friday at work I'd used M-x shell in front of a coworker to commit a source change to Subversion. Emacs' shell doesn't hide passwords, so I unintentionally typed mine in plain-text... in front of someone I would like to actually impress.
Whoops.
Naturally, this morning, I decided to see if anyone had though to deal with this problem, and I discovered
eshell which has actually been part of emacs since v. 21. Just run M-x eshell.There are quite a few things that make eshell different than having emacs open a shell inside of its goofy psuedo-terminal buffer. First of all, it's actually a shell. Just for emacs. Written in elisp. Here are some highlights:
- you can redirect stdout to an emacs buffer. Try env > # <buffer scratch>
- it can be used anywhere that can run emacs, e.g. Win32, or DOS, or a good toaster. Now you don't have to install BASH on Windows to use your Windows box like a Real Computer.
- your aliases are automatically saved between sessions.
- you can use emacs functions like shell commands! Try alias emacs="find-file $1" for an experience in silky-smoothness.
- up and down arrows behave like most shells, cycling through your history. However, left and right arrow allow you place the cursor *behind* the prompt and select text from the output of your last command. I've been looking for this feature in a shell for years now. Eshell makes it easy to copy, say, the PID from a ps and paste it into a "kill."
- it's elisp, so it's easily configurable and extensible.
Subscribe to:
Posts (Atom)

